篇首语:本文由编程笔记#小编为大家整理,主要介绍了Oracle LiveLabs实验:8 Partitioning Techniques in Oracle Database相关的知识,希望对你有一定的参考价值。
此实验关于Oracle Partitioning选件。
此实验申请地址在这里。
实验帮助在这里。
实验宣称需要2小时40分,实际用了4个小时。
Oracle 提供了全面的分区方案来满足每个业务需求。 此外,由于它在 SQL 语句中完全透明,因此分区可以用于任何应用程序,从打包的 OLTP 应用程序到数据仓库。 在本次研讨会中,我们将探索各种分区类型及其相应的用例。
预计工作坊时间:2 小时 40 分钟
Oracle 分区增强了大型数据库的可管理性、性能和可用性。 它提供了全面的分区方法来满足不同的业务需求。 我们可以在事务、数据仓库和混合工作负载应用程序上应用数据库分区,而无需更改任何代码。 我们可以对大型表和索引使用分区,以使它们成为更小的对象,可以在更高级的粒度级别上进行管理和访问。
在 Oracle 数据库中对大型表和索引进行分区可确保为每个业务需求提供最佳方法,并且可以增强几乎所有数据库应用程序的可管理性、性能和可用性。 分区允许将表和索引分解为更小的物理块,同时保持单个对象的逻辑视图。
让我们考虑一下金融服务部门,尤其是零售银行业务,每次我们进行借记、贷记、定期存款、定期存款、汽车 EMI 支付、水电费支付等交易时。 根据 2021 年 12 月 31 日的商业标准报告,它在交易主表中生成一条记录,并且数据呈指数级增长。印度的数字交易量从 2017 财年的 108.5 亿增长到 21 财年的 555.4 亿,复合 年增长率为50.42%。 因此,随着数据量的增长,我们可以将很大一部分历史数据归档到归档存储中,以便按需检索; 然而,即使我们考虑当前财政年度的数据,它在银行层面也有数百万条记录。 在此级别运行查询将花费大量时间并影响整体性能。 最好根据业务需求将数据划分为更小的单元。
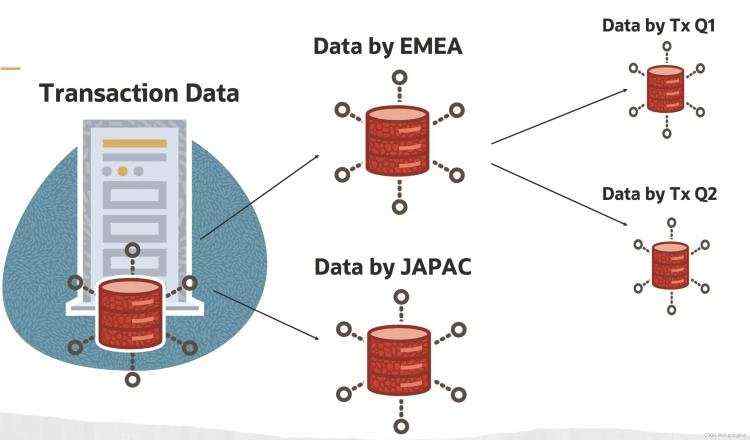
大表难以管理,因此可以将大型数据库和索引拆分成更小、更易于管理的部分。 例如,如果我们的数据库中有太多事件,我们可以轻松地将该表划分为基于区域和月份的事件。

分区的好处:
分区支持数据管理操作,例如。
在本次研讨会中,您将学习如何创建以下分区。
Partitioning whitepaper
Oracle Database Editions
实验环境生成后,单击“View Login Info”可以看到登录信息:
本实验使用的数据库是ADW,即自治数据仓库。
实际上,脚本可以在任何Oracle数据库上运行,而且测试数据很少,最多也就100条。大部分的实验来自Oracle LiveSQL。
原实验是用SQL Developer Web,为了速度和方便,我还是使用了SQL Developer。配置过程略。
范围分区根据您为每个分区建立的分区键值范围将数据映射到分区。 它是与日期一起使用的最常见的分区类型。 例如,您可能希望将销售数据划分为每月分区。 CREATE TABLE 语句的 PARTITION BY RANGE 子句指定表或索引是范围分区的。 PARTITION 子句标识各个分区范围,并且 PARTITION 子句的可选子句可以选择特定于分区段的物理属性和其他属性。
预计实验时间:20 分钟
范围分区是最常见的分区类型,与日期一起使用。 对于以日期列作为分区键的表,January-2010 分区将包含分区键值从 2010 年 1 月 1 日到 2010 年 1 月 31 日的行。
每个分区都有一个 VALUES LESS THAN 子句,该子句指定分区的非包含上限(因为是小于而非小于等于)。 任何等于或高于此文字的分区键值都将添加到下一个更高的分区。 除第一个分区外,所有分区都具有由前一个分区的 VALUES LESS THAN 子句指定的隐式下限。
可以为最高分区定义 MAXVALUE 文字。 MAXVALUE 表示一个虚拟的无限值,其排序高于分区键的任何可能值,包括 NULL 值。
以下是有关美国零售业的一些有趣事实,美国电子商务行业专家预计销售数据将以两位数增长,到 2021 年增长 17.9% 至 9333 亿美元。 电子商务渗透率将继续增加,比 2019 年翻一番还多,到 2025 年达到 23.6%。这意味着不断增长的客户和销售数据量以及其可管理性带来的挑战。 管理如此大量的按时间顺序或销售数据的解决方案是根据日期范围对其进行分区或使用范围分区。
让我们创建范围分区表。 该表使用 sales_date 列的值按范围分区。 分区界限由 VALUES LESS THAN 子句确定。
CREATE TABLE sales_range_partition (
product_id NUMBER(6),
customer_id NUMBER,
channel_id CHAR(1),
promo_id NUMBER(6),
sale_date DATE,
quantity_sold INTEGER,
amount_sold NUMBER(10, 2)
)
PARTITION BY RANGE (
sale_date
)
( PARTITION sales_q1_2014
VALUES LESS THAN ( TO_DATE('01-APR-2014', 'dd-MON-yyyy') ),
PARTITION sales_q2_2014
VALUES LESS THAN ( TO_DATE('01-JUL-2014', 'dd-MON-yyyy') ),
PARTITION sales_q3_2014
VALUES LESS THAN ( TO_DATE('01-OCT-2014', 'dd-MON-yyyy') ),
PARTITION sales_q4_2014
VALUES LESS THAN ( TO_DATE('01-JAN-2015', 'dd-MON-yyyy') )
);
使用此 SQL 查询显示表中的分区。
SET SQLFORMAT ANSICONSOLE
SELECT
table_name,
partition_name,
partition_position,
high_value
FROM
user_tab_partitions
WHERE
table_name = 'SALES_RANGE_PARTITION';
TABLE_NAME PARTITION_NAME PARTITION_POSITION HIGH_VALUE
SALES_RANGE_PARTITION SALES_Q1_2014 1 TO_DATE(' 2014-04-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
SALES_RANGE_PARTITION SALES_Q2_2014 2 TO_DATE(' 2014-07-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
SALES_RANGE_PARTITION SALES_Q3_2014 3 TO_DATE(' 2014-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
SALES_RANGE_PARTITION SALES_Q4_2014 4 TO_DATE(' 2015-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
新增分区:
ALTER TABLE sales_range_partition ADD PARTITION sales_q1_2015
VALUES LESS THAN ( TO_DATE('01-APR-2015', 'dd-MON-yyyy') );
添加新分区后显示表中的分区。
TABLE_NAME PARTITION_NAME PARTITION_POSITION HIGH_VALUE
SALES_RANGE_PARTITION SALES_Q1_2014 1 TO_DATE(' 2014-04-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
SALES_RANGE_PARTITION SALES_Q2_2014 2 TO_DATE(' 2014-07-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
SALES_RANGE_PARTITION SALES_Q3_2014 3 TO_DATE(' 2014-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
SALES_RANGE_PARTITION SALES_Q4_2014 4 TO_DATE(' 2015-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
SALES_RANGE_PARTITION SALES_Q1_2015 5 TO_DATE(' 2015-04-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
将值插入表中。
INSERT INTO sales_range_partition VALUES (1001,100,'A',150,'10-FEB-2014',500,2000);
INSERT INTO sales_range_partition VALUES (1002,110,'B',180,'15-JUN-2014',100,1000);
INSERT INTO sales_range_partition VALUES (1001,100,'A',150,'20-AUG-2014',500,2000);
COMMIT;
显示表中指定分区的数据。
SELECT * FROM sales_range_partition PARTITION(sales_q1_2014);
PRODUCT_ID CUSTOMER_ID CHANNEL_ID PROMO_ID SALE_DATE QUANTITY_SOLD AMOUNT_SOLD
1001 100 A 150 10-FEB-14 500 2000
显示表中的所有数据。
SELECT * FROM sales_range_partition;
PRODUCT_ID CUSTOMER_ID CHANNEL_ID PROMO_ID SALE_DATE QUANTITY_SOLD AMOUNT_SOLD
1001 100 A 150 10-FEB-14 500 2000
1002 110 B 180 15-JUN-14 100 1000
1001 100 A 150 20-AUG-14 500 2000
DROP TABLE sales_range_partition;
Range Partitioning
Database VLDB and Partitioning Guide
间隔分区是范围分区的扩展,其中数据库表分区是基于间隔完成的,而不仅仅是日期本身。 CREATE TABLE 语句的 INTERVAL 子句为表建立间隔分区。 您必须使用 PARTITION 子句指定至少一个范围分区。 范围分区键值决定了范围分区的高值,称为过渡点。 数据库会自动为超出该转换点的数据创建间隔分区。 每个区间分区的下边界是前一个范围或区间分区的非包含上边界。
预计实验时间:20 分钟
当业务分析师想要查看每日、每月、每季度或每年的销售数据时,例如,在金融服务或零售行业中,根据间隔对数据进行分区会更容易。 随着数据的增长,分区会不断自动创建。
让我们创建间隔分区表。 以下示例指定两个分区,其间隔宽度为一个月。
CREATE TABLE interval_par_demo (
start_date DATE,
store_id NUMBER,
inventory_id NUMBER(6),
qty_sold NUMBER(3)
)
PARTITION BY RANGE (
start_date
) INTERVAL ( numtoyminterval(1, 'MONTH') ) ( PARTITION interval_par_demo_p2
VALUES LESS THAN ( TO_DATE('1-7-2007', 'DD-MM-YYYY') ),
PARTITION interval_par_demo_p3
VALUES LESS THAN ( TO_DATE('1-8-2007', 'DD-MM-YYYY') )
);
插入记录:
insert into interval_par_demo (start_date, store_id, inventory_id, qty_sold)
values ( '15-AUG-07', 1, 1, 1);
insert into interval_par_demo (start_date, store_id, inventory_id, qty_sold)
values ( '15-SEP-07', 1, 1, 1);
查看 USER_TAB_PARTITIONS 表中的数据:
SELECT
table_name,
partition_name,
partition_position,
high_value
FROM
user_tab_partitions
WHERE
table_name = 'INTERVAL_PAR_DEMO'
ORDER BY
partition_name;
TABLE_NAME PARTITION_NAME PARTITION_POSITION HIGH_VALUE
INTERVAL_PAR_DEMO INTERVAL_PAR_DEMO_P2 1 TO_DATE(' 2007-07-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
INTERVAL_PAR_DEMO INTERVAL_PAR_DEMO_P3 2 TO_DATE(' 2007-08-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
INTERVAL_PAR_DEMO SYS_P1891 3 TO_DATE(' 2007-09-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
INTERVAL_PAR_DEMO SYS_P1892 4 TO_DATE(' 2007-10-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIAN')
这里 SYS_P1891 和 SYS_P1892 是基于间隔自动生成的分区。 让我们验证新创建的分区中的数据。 请注意,自动生成的分区名称可能因您的实例而异。
SELECT * FROM interval_par_demo PARTITION(SYS_P1891);
START_DATE STORE_ID INVENTORY_ID QTY_SOLD
15-AUG-07 1 1 1
SELECT * FROM interval_par_demo PARTITION(SYS_P1892);
START_DATE STORE_ID INVENTORY_ID QTY_SOLD
15-SEP-07 1 1 1
drop table interval_par_demo purge;
Interval Partitioning
Database VLDB and Partitioning Guide
列表分区使您能够通过为每个分区的描述中的每个分区键指定离散值列表来显式控制行映射到分区的方式。 列表分区的优点是可以对无序和不相关的数据集进行分组和组织。 对于以 region 列作为分区键的表,East Sales Region 分区可能包含 New York、Virginia 和 Florida 值。 创建列表分区的语义类似于创建范围分区的语义。
创建列表分区的语义类似于创建范围分区的语义。 您在 CREATE TABLE 语句中指定 PARTITION BY LIST 子句来创建列表分区。 分区键可以是用于列表分区的表中的一个或多个列名。
预计实验时间:20 分钟
与范围分区不同,使用列表分区的分区之间没有明显的顺序感。 您还可以指定一个默认分区,将不映射到任何其他分区的行映射到该分区。
天气预报是通过收集有关给定地点当前大气的定量数据并使用气象学来预测大气将如何变化来进行的。 天气预报是经济的一部分。 例如,2009 年,美国在天气预报上花费了大约 51 亿美元,产生的收益估计是原来的六倍。 数据量不断增长,分析以前的区域数据可能是性能密集型的。 由于天气数据具有地理位置、日期、温度和湿度的变化,因此这是基于区域值列表或使用列表分区对数据进行分区的好案例。 另一个很好的例子是基于区域划分销售数据以用于业务报告,如下面的任务列表所示。
创建列表分区表:
CREATE TABLE sales_by_region (
product_id NUMBER(6),
quantity_sold INTEGER,
sale_date DATE,
store_name VARCHAR(30),
state_code VARCHAR(2)
)
PARTITION BY LIST (state_code)
(
PARTITION region_east
VALUES ('CT','MA','MD','ME','NH','NJ','NY','PA','VA'),
PARTITION region_west
VALUES ('AZ','CA','CO','NM','NV','OR','UT','WA'),
PARTITION region_south
VALUES ('AL','AR','GA','KY','LA','MS','TN','TX'),
PARTITION region_central
VALUES ('IA','IL','MO','MI','ND','OH','SD')
);
查看 user_tab_partitions 表中的数据:
SELECT
table_name,
partition_name,
partition_position,
high_value
FROM
user_tab_partitions
WHERE
table_name = 'SALES_BY_REGION';
TABLE_NAME PARTITION_NAME PARTITION_POSITION HIGH_VALUE
SALES_BY_REGION REGION_EAST 1 'CT', 'MA', 'MD', 'ME', 'NH', 'NJ', 'NY', 'PA', 'VA'
SALES_BY_REGION REGION_WEST 2 'AZ', 'CA', 'CO', 'NM', 'NV', 'OR', 'UT', 'WA'
SALES_BY_REGION REGION_SOUTH 3 'AL', 'AR', 'GA', 'KY', 'LA', 'MS', 'TN', 'TX'
SALES_BY_REGION REGION_CENTRAL 4 'IA', 'IL', 'MO', 'MI', 'ND', 'OH', 'SD'
-- 向表中添加一个新分区。
ALTER TABLE sales_by_region ADD PARTITION region_nonmainland VALUES ('HI','PR');
-- 在表中添加新分区以容纳 NULL 值。
ALTER TABLE sales_by_region ADD PARTITION region_null VALUES (NULL);
-- 为不映射到任何其他分区的值添加一个新分区到表中。
ALTER TABLE sales_by_region ADD PARTITION VALUES (DEFAULT);
-- 添加新分区后显示表中的分区。
SELECT
table_name,
partition_name,
partition_position,
high_value
FROM
user_tab_partitions
WHERE
table_name = 'SALES_BY_REGION';
TABLE_NAME PARTITION_NAME PARTITION_POSITION HIGH_VALUE
SALES_BY_REGION REGION_EAST 1 'CT', 'MA', 'MD', 'ME', 'NH', 'NJ', 'NY', 'PA', 'VA'
SALES_BY_REGION REGION_WEST 2 'AZ', 'CA', 'CO', 'NM', 'NV', 'OR', 'UT', 'WA'
SALES_BY_REGION REGION_SOUTH 3 'AL', 'AR', 'GA', 'KY', 'LA', 'MS', 'TN', 'TX'
SALES_BY_REGION REGION_CENTRAL 4 'IA', 'IL', 'MO', 'MI', 'ND', 'OH', 'SD'
SALES_BY_REGION REGION_NONMAINLAND 5 'HI', 'PR'
SALES_BY_REGION REGION_NULL 6 NULL
SALES_BY_REGION SYS_P1893 7 DEFAULT
7 rows selected.
-- 将新值添加到分区键列表中。
ALTER TABLE sales_by_region MODIFY PARTITION region_central ADD VALUES ('OK','KS');
-- 修改分区后显示表中的分区。
SELECT
table_name,
partition_name,
partition_position,
high_value
FROM
user_tab_partitions
WHERE
table_name = 'SALES_BY_REGION';
TABLE_NAME PARTITION_NAME PARTITION_POSITION HIGH_VALUE
SALES_BY_REGION REGION_EAST 1 'CT', 'MA', 'MD', 'ME', 'NH', 'NJ', 'NY', 'PA', 'VA'
SALES_BY_REGION REGION_WEST 2 'AZ', 'CA', 'CO', 'NM', 'NV', 'OR', 'UT', 'WA'
SALES_BY_REGION REGION_SOUTH 3 'AL', 'AR', 'GA', 'KY', 'LA', 'MS', 'TN', 'TX'
SALES_BY_REGION REGION_CENTRAL 4 'IA', 'IL', 'MO', 'MI', 'ND', 'OH', 'SD', 'OK', 'KS'
SALES_BY_REGION REGION_NONMAINLAND 5 'HI', 'PR'
SALES_BY_REGION REGION_NULL 6 NULL
SALES_BY_REGION SYS_P1893 7 DEFAULT
7 rows selected.
-- 将值插入表中。
INSERT INTO sales_by_region VALUES (1001,100,'25-AUG-2014','My Store MA','MA');
INSERT INTO sales_by_region VALUES (1002,200,'26-AUG-2014','My Store OK','OK');
COMMIT;
-- 显示表中的所有数据。
SELECT * FROM sales_by_region;
PRODUCT_ID QUANTITY_SOLD SALE_DATE STORE_NAME STATE_CODE
1001 100 25-AUG-14 My Store MA MA
1002 200 26-AUG-14 My Store OK OK
显示表中指定分区的数据。
SELECT * FROM sales_by_region PARTITION(region_east);
PRODUCT_ID QUANTITY_SOLD SALE_DATE STORE_NAME STATE_CODE
1001 100 25-AUG-14 My Store MA MA
drop table sales_by_region purge;
List Partitioning
Database VLDB and Partitioning Guide
散列分区根据 Oracle 的散列算法将数据映射到分区到您识别的分区键。 散列算法在分区之间均匀分布行,使分区大小大致相同。 复合 hash-* 分区允许沿两个维度进行散列分区。 复合 hash-hash 分区策略在复合 hash-* 分区表中具有最大的商业价值。 这种技术有利于沿二维进行分区连接。
预计实验室时间:20 分钟
哈希分区是跨设备均匀分布数据的理想方法。 哈希分区也是范围分区的一种易于使用的替代方案,主要是在分区的数据不是历史数据或没有明显的分区键时。
在常规电子商务网站中,产品列表、过滤和排序决定了客户浏览产品目录的难易程度。 在 UI 专家的可用性测试中,客户购买组织良好且易于查找的产品的可能性很大。 下面是一个简单的示例,说明如何为板球运动装备对在线商店数据进行哈希分区,其中每个(球棒、球等)都被命名为表空间。
CREATE TABLE cricketset (
id NUMBER,
name VARCHAR2(60)
)
PARTITION BY HASH ( id ) PARTITIONS 7 STORE IN ( bat, ball, stumps, wicket, gloves, pads, guards );
让我们创建一个以客户id为哈希值的间隔哈希分区表,对2016年之前和2016年之后的数据进行分区。
-- 一级是间隔分区,二级是哈希分区
CREATE TABLE sales_interval_hash (
prod_id NUMBER(6),
cust_id NUMBER,
time_id DATE,
channel_id CHAR(1),
promo_id NUMBER(6),
quantity_sold NUMBER(3),
amount_sold NUMBER(10, 2)
)
PARTITION BY RANGE ( time_id ) INTERVAL ( numtoyminterval(1, 'MONTH') )
SUBPARTITION BY HASH ( cust_id ) SUBPARTITIONS 4
( PARTITION before_2016
VALUES LESS THAN ( TO_DATE('01-JAN-2016', 'dd-MON-yyyy'



![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)


 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 